在當(dāng)今信息爆炸的時代,如何從海量數(shù)據(jù)中高效地提取、組織并洞察知識,成為各行各業(yè)面臨的共同挑戰(zhàn)。知識圖譜作為一種結(jié)構(gòu)化的語義知識庫,以其強大的關(guān)聯(lián)分析能力和直觀的可視化表現(xiàn)形式,正在成為解決這一問題的關(guān)鍵技術(shù)。本文將以一個典型的項目流程為例,詳細(xì)介紹如何從網(wǎng)絡(luò)數(shù)據(jù)抓取開始,一步步構(gòu)建、存儲并最終可視化一個知識圖譜,涵蓋爬蟲技術(shù)、數(shù)據(jù)處理、數(shù)據(jù)庫存儲與可視化展現(xiàn)的全過程。
第一步:數(shù)據(jù)獲取——定向網(wǎng)絡(luò)爬蟲
構(gòu)建知識圖譜的第一步是獲取原始數(shù)據(jù)。對于公開的網(wǎng)絡(luò)資源,如技術(shù)博客、百科站點等,編寫定向爬蟲是常見且高效的方法。以CSDN博客為例,我們可以使用Python的requests、BeautifulSoup或Scrapy框架來抓取目標(biāo)文章。
關(guān)鍵任務(wù)包括:
1. 確定目標(biāo)與范圍: 明確需要采集的領(lǐng)域,例如“人工智能”、“大數(shù)據(jù)”或“后端開發(fā)”相關(guān)的博客。
2. 分析頁面結(jié)構(gòu): 解析博客列表頁和詳情頁的HTML結(jié)構(gòu),定位標(biāo)題、正文、作者、標(biāo)簽、發(fā)布時間等關(guān)鍵信息的CSS選擇器或XPath。
3. 編寫爬蟲程序: 實現(xiàn)自動翻頁、請求去重、異常處理(如反爬機(jī)制應(yīng)對、網(wǎng)絡(luò)超時)等功能,并遵守網(wǎng)站的robots.txt協(xié)議,合理設(shè)置請求間隔,做到友好爬取。
4. 數(shù)據(jù)初步清洗: 在抓取過程中或之后,立即去除HTML標(biāo)簽、無關(guān)廣告文本、空白字符等,將非結(jié)構(gòu)化文本轉(zhuǎn)化為相對規(guī)整的純文本數(shù)據(jù)。
第二步:數(shù)據(jù)處理與知識抽取
獲取的原始文本數(shù)據(jù)需要經(jīng)過深度處理,才能提煉出構(gòu)成知識圖譜的“實體”和“關(guān)系”。這是構(gòu)建圖譜的核心環(huán)節(jié)。
核心流程如下:
1. 實體識別: 利用自然語言處理技術(shù),從博客正文、標(biāo)題和標(biāo)簽中識別出關(guān)鍵實體。例如,人名(專家、作者)、技術(shù)術(shù)語(如“TensorFlow”、“Spark”)、組織機(jī)構(gòu)、項目名等。可以采用基于規(guī)則的方法、預(yù)訓(xùn)練模型(如BERT、ERNIE)或現(xiàn)有工具庫(如HanLP、Stanford NLP)。
2. 關(guān)系抽取: 確定實體之間的語義關(guān)系。例如,“作者-撰寫-博客”、“技術(shù)A-相似于-技術(shù)B”、“技術(shù)-屬于-領(lǐng)域”。這可以通過分析句法結(jié)構(gòu)、依賴關(guān)系或使用關(guān)系分類模型來實現(xiàn)。對于技術(shù)博客,關(guān)系常常隱含在行文之中(如“對比”、“基于”、“應(yīng)用于”)。
3. 屬性抽取: 為實體補充屬性信息,如技術(shù)的發(fā)布日期、作者的單位、博客的閱讀量等。
4. 知識融合與消歧: 將不同來源或不同表述的同一實體進(jìn)行合并(如“機(jī)器學(xué)習(xí)”和“ML”指向同一概念),并解決同名實體歧義問題(如“蘋果”公司 vs. “蘋果”水果)。
經(jīng)過此步驟,我們得到了結(jié)構(gòu)化的三元組數(shù)據(jù)集合:(頭實體,關(guān)系,尾實體) 或 (實體,屬性,值)。
第三步:數(shù)據(jù)存儲——圖數(shù)據(jù)庫的選擇與應(yīng)用
知識圖譜的本質(zhì)是圖結(jié)構(gòu)數(shù)據(jù),因此使用專門的圖數(shù)據(jù)庫進(jìn)行存儲和查詢是最佳選擇。Neo4j是目前最流行的原生圖數(shù)據(jù)庫之一。
存儲操作要點:
1. 設(shè)計圖模式: 根據(jù)抽取出的實體、關(guān)系和屬性,設(shè)計節(jié)點標(biāo)簽、關(guān)系類型和屬性鍵。例如,創(chuàng)建Technology、Author、Blog等節(jié)點標(biāo)簽,以及WROTE、MENTIONS、RELATED_TO等關(guān)系類型。
2. 數(shù)據(jù)導(dǎo)入: 將上一步處理好的三元組數(shù)據(jù),通過Neo4j的Cypher查詢語言批量導(dǎo)入數(shù)據(jù)庫。例如:`cypher
CREATE (a:Author {name: '張三'}), (b:Blog {title: '知識圖譜入門'})
CREATE (a)-[:WROTE {time: '2023-10-01'}]->(b)`
- 建立索引: 對經(jīng)常查詢的實體屬性(如
name、title)建立索引,以大幅提升查詢速度。
使用圖數(shù)據(jù)庫的優(yōu)勢在于,它能夠高效地執(zhí)行復(fù)雜的關(guān)聯(lián)查詢(如多跳查詢、路徑查找),這是傳統(tǒng)關(guān)系型數(shù)據(jù)庫難以勝任的。
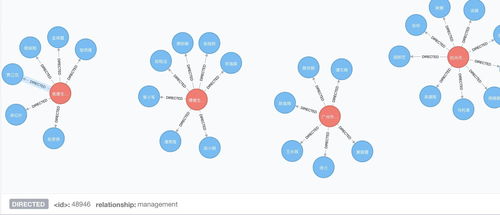
第四步:知識可視化與交互式探索
將存儲在數(shù)據(jù)庫中的知識圖譜直觀地展示出來,是發(fā)揮其價值的關(guān)鍵。可視化有助于快速發(fā)現(xiàn)模式、洞察關(guān)聯(lián)。
實現(xiàn)方式:
1. 后端API: 使用Python的Flask或FastAPI框架搭建一個Web服務(wù)后端。該后端負(fù)責(zé)連接Neo4j數(shù)據(jù)庫,接收前端的查詢請求(例如“展示與‘神經(jīng)網(wǎng)絡(luò)’相關(guān)的所有技術(shù)和博客”),執(zhí)行Cypher查詢,并將結(jié)果以JSON格式返回給前端。
2. 前端可視化: 使用專業(yè)的圖可視化JavaScript庫,如ECharts、G6、Cytoscape.js或D3.js。這些庫能夠?qū)⒐?jié)點和關(guān)系數(shù)據(jù)渲染成可交互的力導(dǎo)向圖、網(wǎng)狀圖等。用戶可以點擊節(jié)點查看詳情、拖拽布局、放大縮小、高亮關(guān)聯(lián)路徑等。
3. 集成與分析: 在可視化界面中,可以集成簡單的分析功能,如計算節(jié)點的度中心性(重要性)、查找兩個實體之間的最短路徑、進(jìn)行社區(qū)發(fā)現(xiàn)(聚類)等,從而挖掘更深層的知識。
應(yīng)用與展望
通過以上流程構(gòu)建的知識圖譜,可以應(yīng)用于多種場景:
- 智能搜索與推薦: 超越關(guān)鍵詞匹配,實現(xiàn)語義搜索(如搜索“深度學(xué)習(xí)框架”,能返回TensorFlow、PyTorch等相關(guān)實體及其關(guān)聯(lián)內(nèi)容),并基于圖譜關(guān)聯(lián)進(jìn)行內(nèi)容推薦。
- 領(lǐng)域知識梳理: 快速構(gòu)建某個技術(shù)領(lǐng)域(如“云原生”)的知識全景圖,厘清技術(shù)棧、工具鏈和核心概念之間的關(guān)系。
- 趨勢分析: 結(jié)合時間屬性,分析不同技術(shù)熱度的演變趨勢及關(guān)聯(lián)技術(shù)的共現(xiàn)規(guī)律。
****,從爬蟲抓取、信息抽取到圖數(shù)據(jù)庫存儲與可視化,構(gòu)建知識圖譜是一個系統(tǒng)性的工程。它融合了網(wǎng)絡(luò)爬蟲、自然語言處理、數(shù)據(jù)庫技術(shù)和數(shù)據(jù)可視化等多個領(lǐng)域的技術(shù)。隨著技術(shù)的不斷發(fā)展,自動化抽取的精度、大規(guī)模圖譜的存儲計算效率以及交互式可視化的體驗都將持續(xù)提升,使得知識圖譜在更廣泛的領(lǐng)域發(fā)揮其“智慧大腦”的作用。